When people talk about artificial intelligence, especially deep learning, the conversation usually centers around accuracy and performance. How well does the model classify images? Can it outperform humans in pattern recognition? While these questions are valid, they miss a crucial piece of the puzzle: explainability.
Explainability is about understanding why an AI model makes a specific prediction. In high-stakes domains like healthcare, finance, or criminal justice, knowing the why is just as important as the what. Yet this topic is often overlooked in favor of performance benchmarks.
Why Is Explainability Hard in Deep Learning?
Classical models like decision trees (e.g., CART) offer built-in transparency. You can trace the decision path from root to leaf and understand the model’s logic. But deep learning models are different. They operate through layers of nonlinear transformations and millions of parameters. As a result, even domain experts can find their predictions opaque.
This can lead to problems:
- Lack of trust from users or stakeholders
- Difficulty debugging or improving models
- Potential for hidden biases or unfair decisions
This is where explainability tools come in.
Tools That Help Open the Black Box
Two widely used frameworks for model explanation are LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations). Both aim to provide insights into which features influenced a specific prediction and by how much.
LIME in Action
LIME works by perturbing the input data and observing how the model’s predictions change. For instance, in a text classification task, LIME can highlight which words in an email led the model to flag it as spam. It does this by creating many variations of the email (e.g., removing or replacing words) and observing the output.
Loan Risk Example:
- A model classifies a loan application as risky. We will use John as an example.
- We want to find the reasons as to why their application was labeled as risky.
- LIME reveals that the applicant’s job status and credit utilization were the two most influential factors.
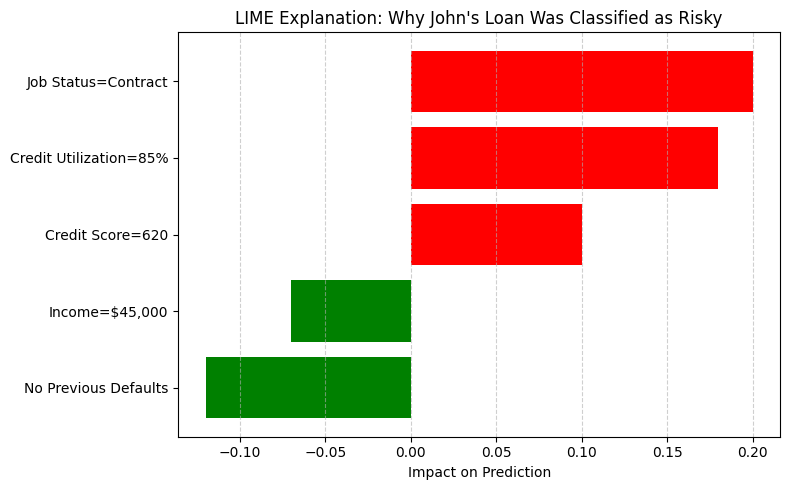
LIME reveals that the model flagged John’s loan as risky mainly due to his contract employment status and high credit utilization. Although John had no previous defaults and a moderate income, those factors were outweighed by the others in the model’s decision.
SHAP in Practice
SHAP uses concepts from cooperative game theory to assign each feature an importance value. It ensures a more consistent and mathematically grounded explanation. SHAP values can be plotted to show how each input feature pushes the prediction higher or lower.
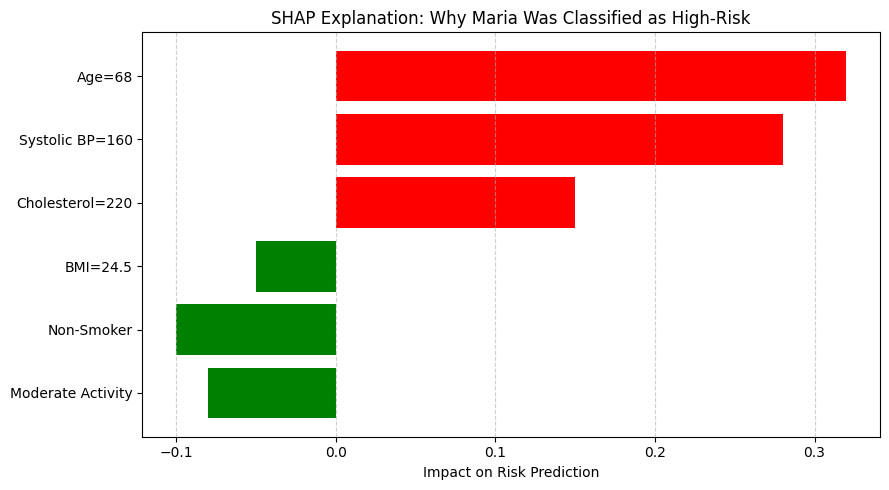
Medical Diagnosis Example:
- Let’s use Maria as an example, after her information was entered into the system, she was classified as high risk by the model
- To understand as to what factors contributed to that classification, we can use SHAP. SHAP shows that age and blood pressure significantly contributed to a high-risk prediction.
- These insights help physicians verify if the model aligns with clinical reasoning.
Final Thoughts
The examples of Maria and John illustrate a powerful truth: even highly accurate models are incomplete without explanations. When a model labels someone as high-risk, whether for a disease or a loan default, it’s not enough to accept the outcome at face value. We need to understand why the model made that decision.
Tools like LIME and SHAP make this possible. They open up the black box and allow us to see which features mattered most, giving decision-makers the context they need to trust or challenge the model’s output.
Why Explainability Matters in Business:
- Builds trust with stakeholders
- Supports accountability in sensitive decisions
- Uncovers potential biases or errors in the model
- Aligns predictions with domain expertise
As AI becomes more embedded in real-world systems, explainability is not optional; it’s essential. It turns predictions into insights, and insights into informed, ethical decisions.
Good AI model evaluations doesn’t stop at explainability. Learn the importance of consistency and faithfulness and see why it matters by checking out this post.