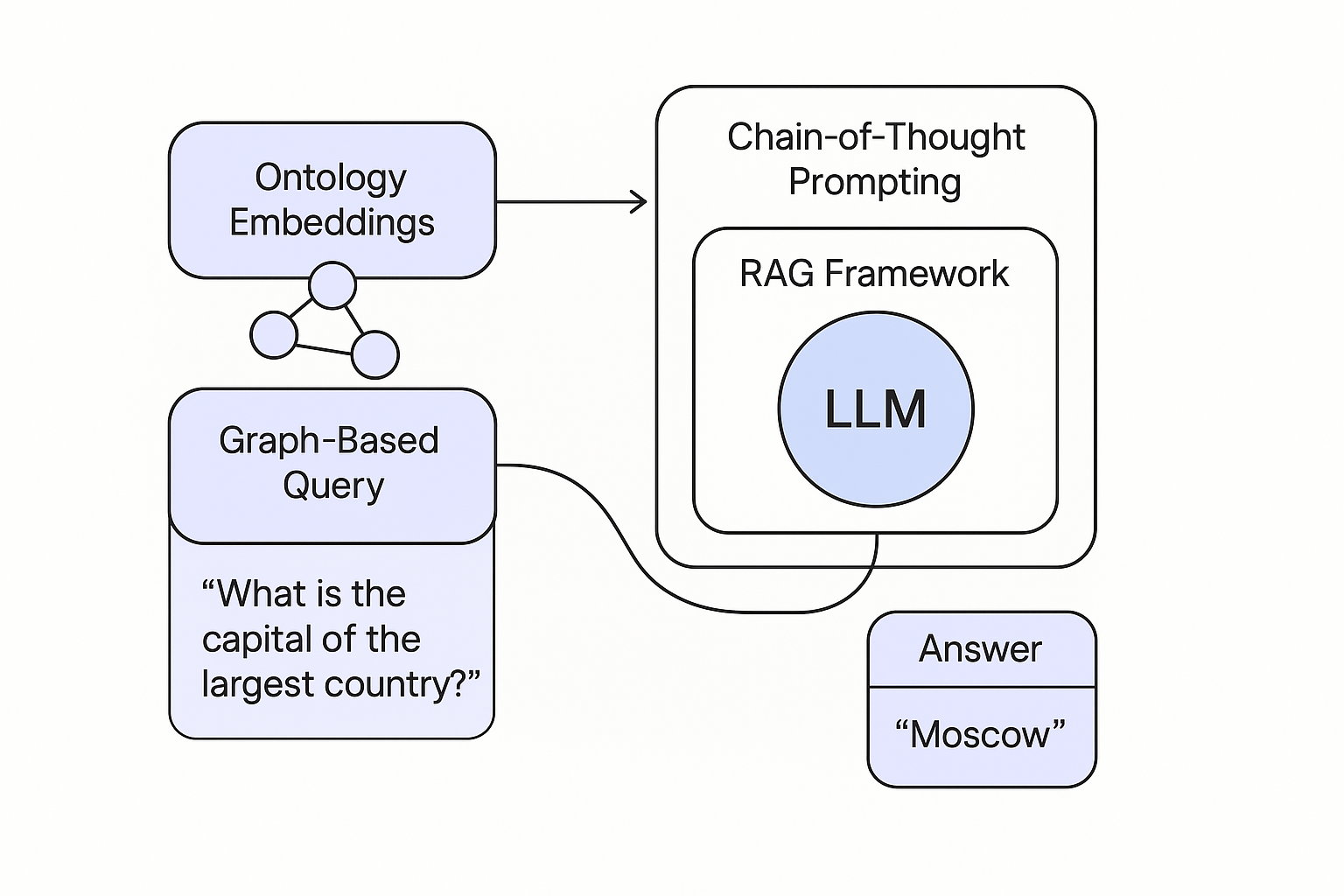
In the rapidly evolving landscape of enterprise AI, organizations often grapple with a common challenge: enabling large language models (LLMs) to interpret and respond to queries based on structured data, such as knowledge graphs, without necessitating frequent retraining as the data evolves.
A novel approach addresses this issue by integrating three key methodologies:
- Ontology embeddings : Transform structured data into formats that LLMs can process, facilitating an understanding of relationships, hierarchies, and schema definitions within the data.
- Chain-of-Thought prompting: Encourage LLMs to engage in step-by-step reasoning, enhancing their ability to navigate complex data structures and derive logical conclusions.
- Retrieval-Augmented Generation (RAG): Equip models to retrieve pertinent information from databases or knowledge graphs prior to generating responses, ensuring that outputs are both accurate and contextually relevant.
By synergizing these techniques, organizations can develop more intelligent and efficient systems for querying knowledge graphs without the need for continuous model retraining.
Implementation Strategy
- Combining Ontology Embeddings with Chain-of-Thought Prompting: This fusion allows LLMs to grasp structured knowledge and reason through it methodically, which is particularly beneficial when dealing with intricate data relationships.
- Integrating within a RAG Framework: Traditionally used for unstructured data, RAG can be adapted to retrieve relevant segments from knowledge graphs, providing LLMs with the necessary context for informed response generation.
- Facilitating Zero/Few-Shot Reasoning: This approach minimizes the need for retraining by utilizing well-structured prompts, enabling LLMs to generalize across various datasets and schemas effectively.
Organizational Benefits
Adopting this methodology offers several advantages:
- Reduced Need for Retraining: Systems can adapt to evolving data without the overhead of continuous model updates.
- Enhanced Explainability: The step-by-step reasoning process provides transparency in AI-driven decisions.
- Improved Performance with Complex Data: The model’s ability to comprehend and navigate structured data leads to more accurate responses.
- Adaptability to Schema Changes: The system remains resilient amidst modifications in data structures.
- Efficient Deployment Across Domains: LLMs can be utilized across various sectors without domain-specific fine-tuning.
Practical Applications
This approach has been successfully implemented in large-scale systems, such as the Dutch national cadastral knowledge graph (Kadaster), demonstrating its viability in real-world scenarios. For instance, deploying a chatbot capable of:
- Understanding domain-specific relationships without explicit programming.
- Updating its knowledge base in tandem with data evolution.
- Operating seamlessly across departments with diverse taxonomies.
- Delivering transparent and traceable answers in critical domains.
Conclusion
By integrating ontology-aware prompting, systematic reasoning, and retrieval-enhanced generation, organizations can develop AI systems that interact with structured data more effectively. This strategy not only streamlines the process but also enhances the reliability and adaptability of AI applications in data-intensive industries. For a comprehensive exploration of this methodology, refer to Bolin Huang’s Master’s thesis.