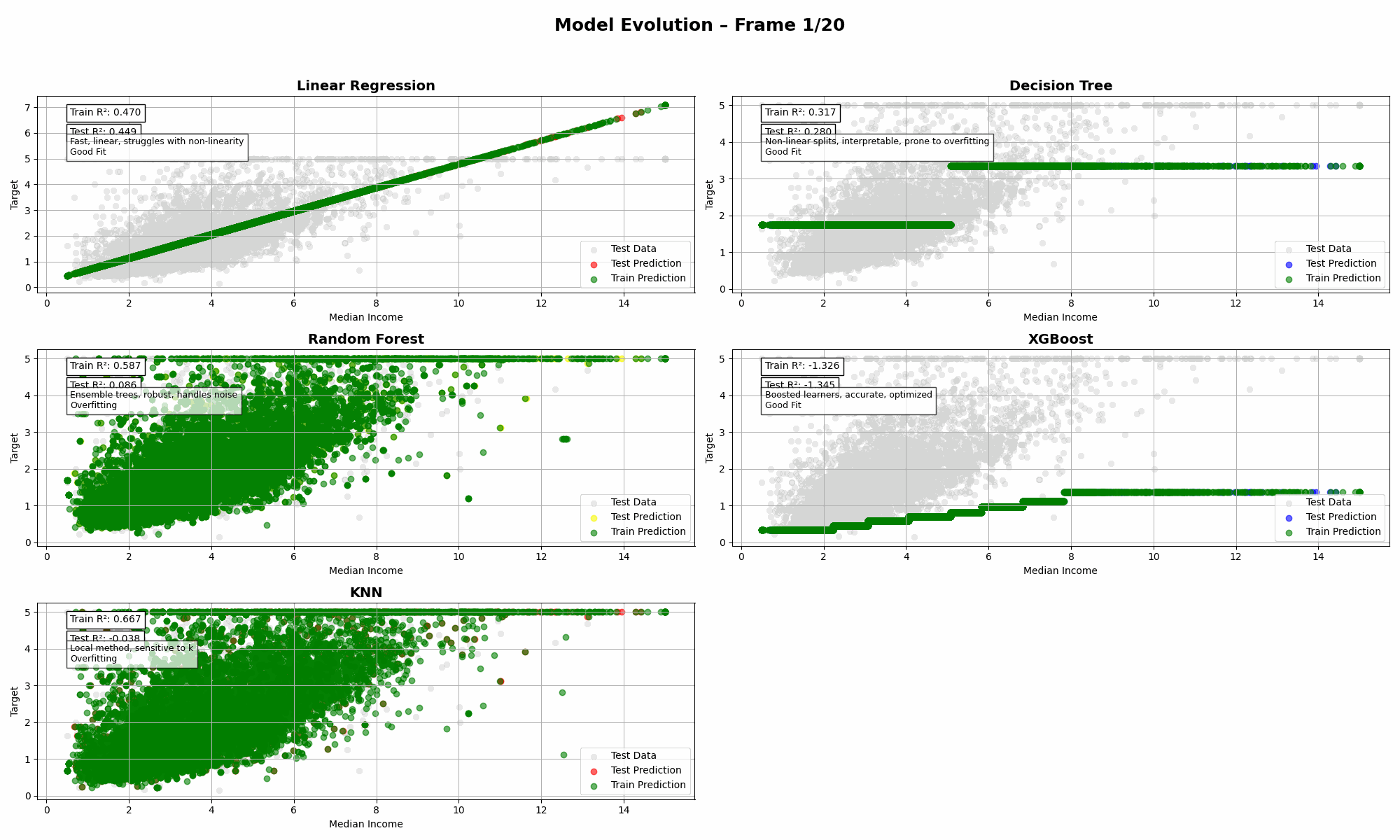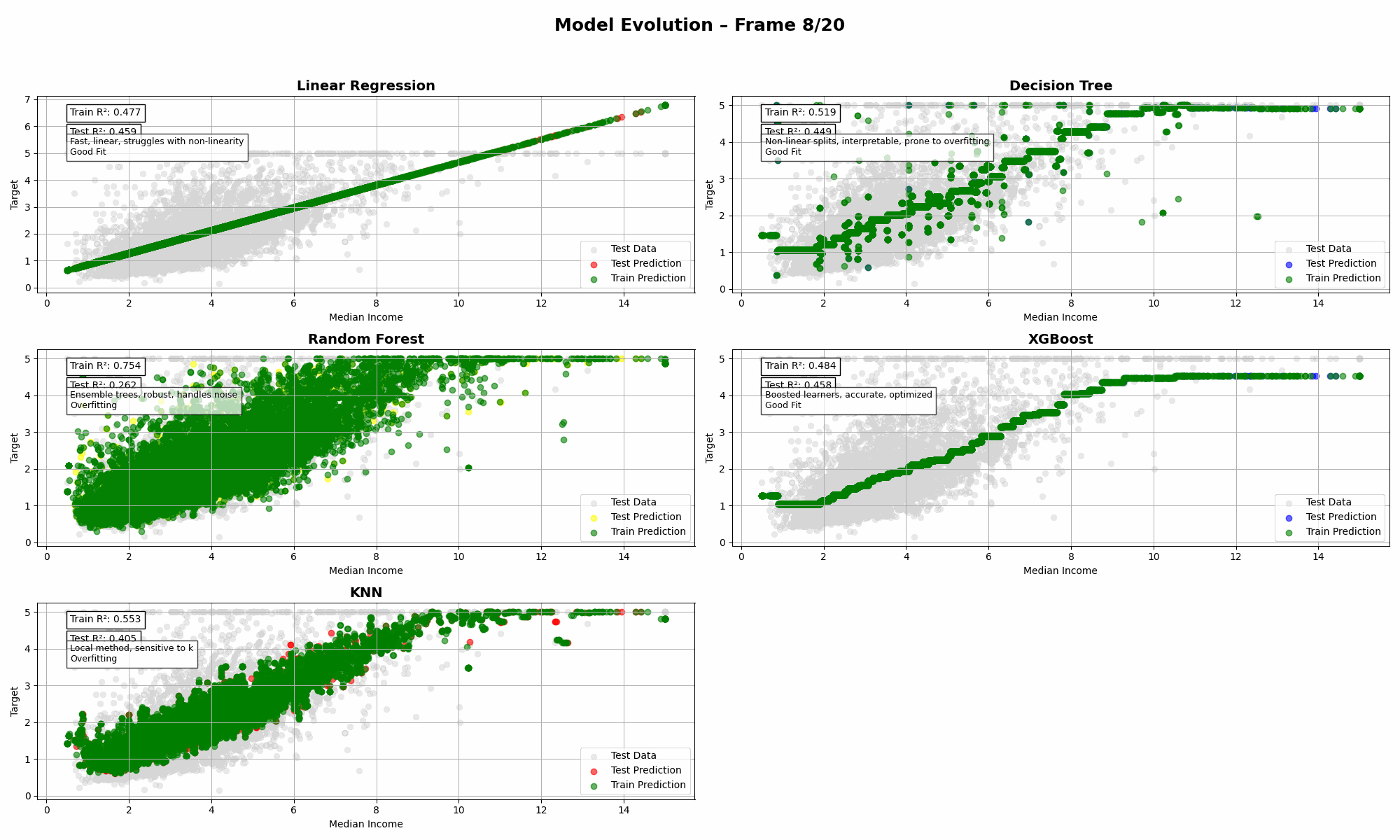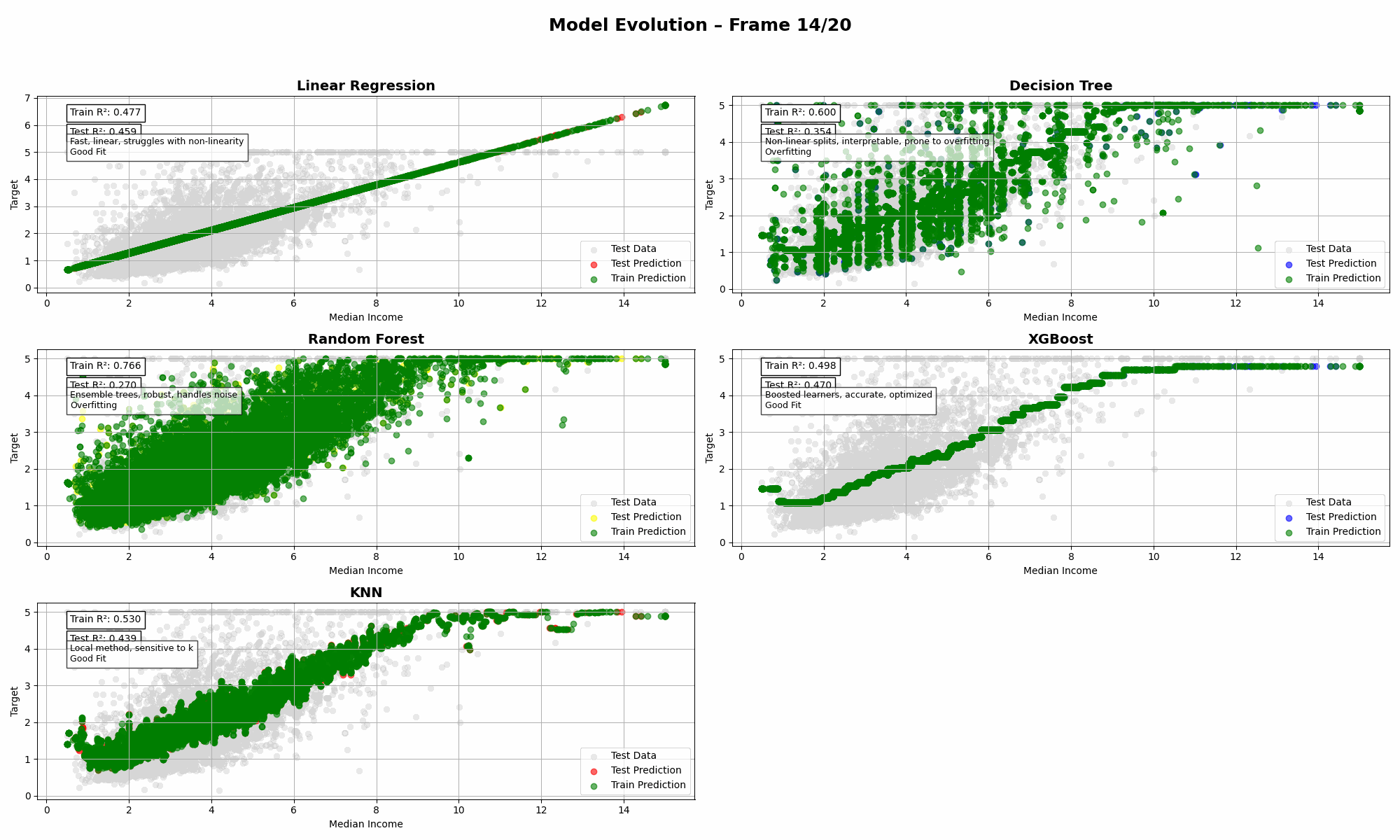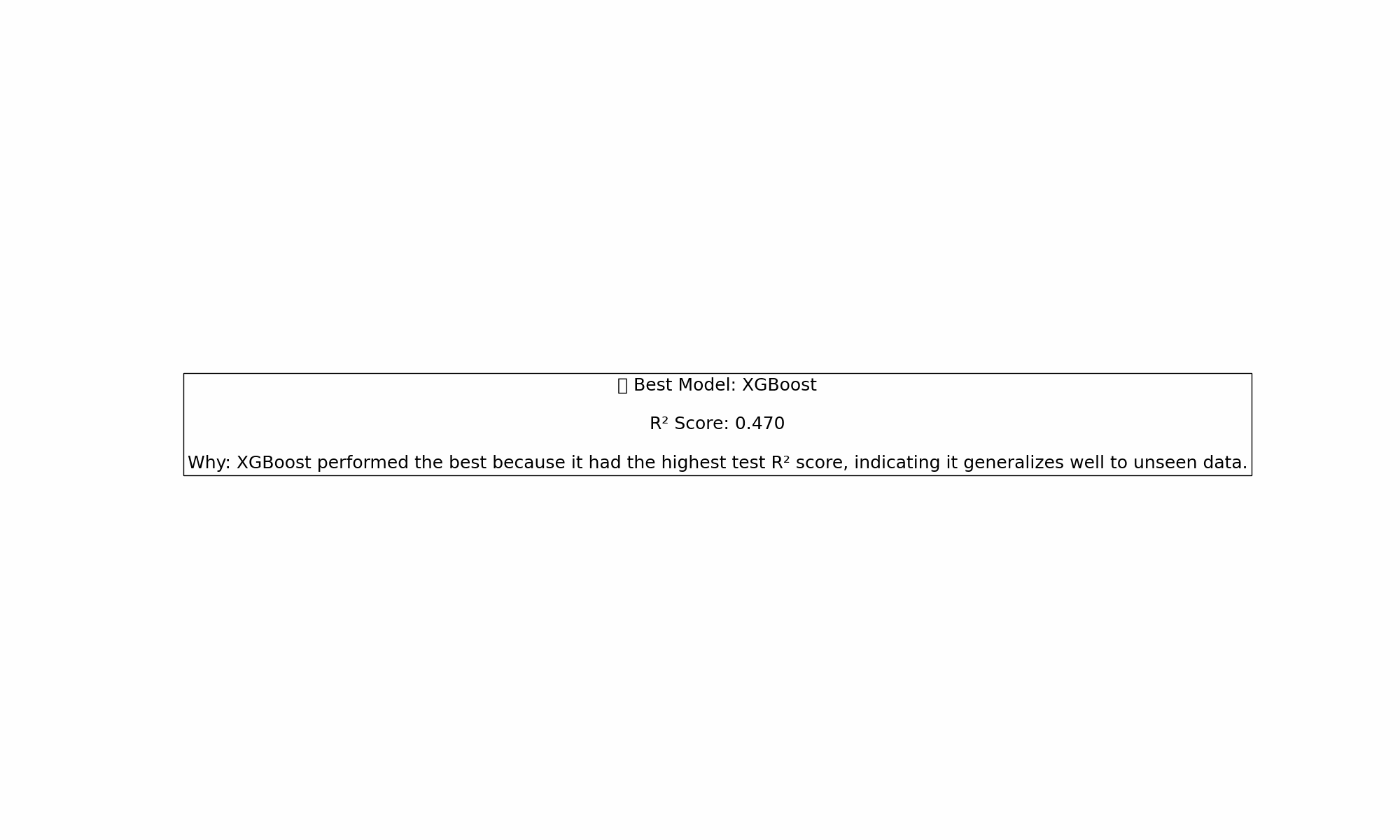
Imagine throwing five regressors into the same ring, giving them the same dataset, and watching them wrestle with reality. That’s what this animation is all about: a visual deep dive into bias, variance, and model complexity—without the textbook-level headache.
The models in play
Five well-known regression models, one smooth sinusoidal target function, and a bunch of noisy data points:
- Linear Regression – The straight-line enthusiast.
- Decision Tree – Thinks in boxes, and sometimes forgets how to generalize.
- Random Forest – The chill ensemble kid who smooths out the chaos.
- XGBoost – The overachiever with a calculator and an ego.
- KNN – Your nosy neighbor who always asks, “What are your closest friends doing?”
🎥 The Animation:
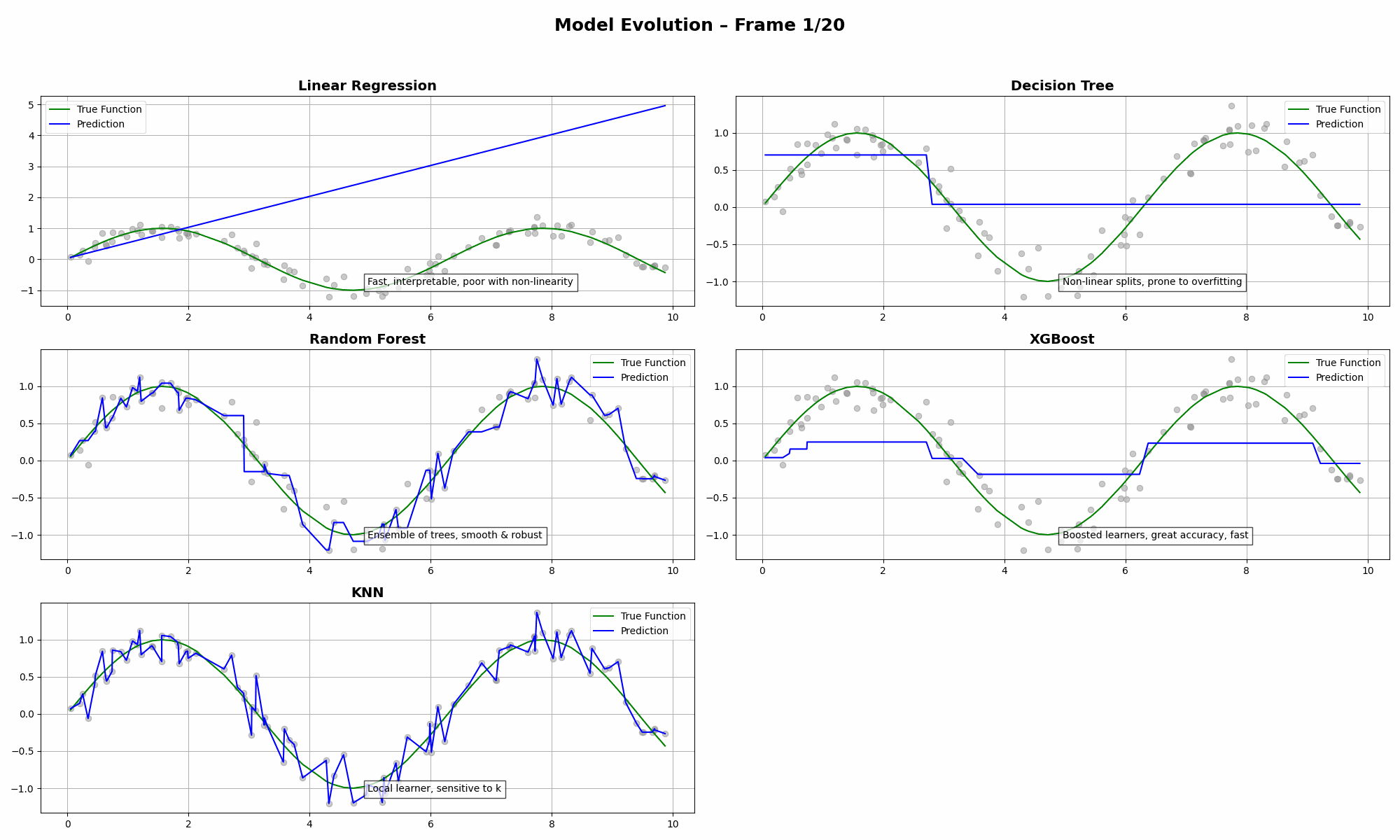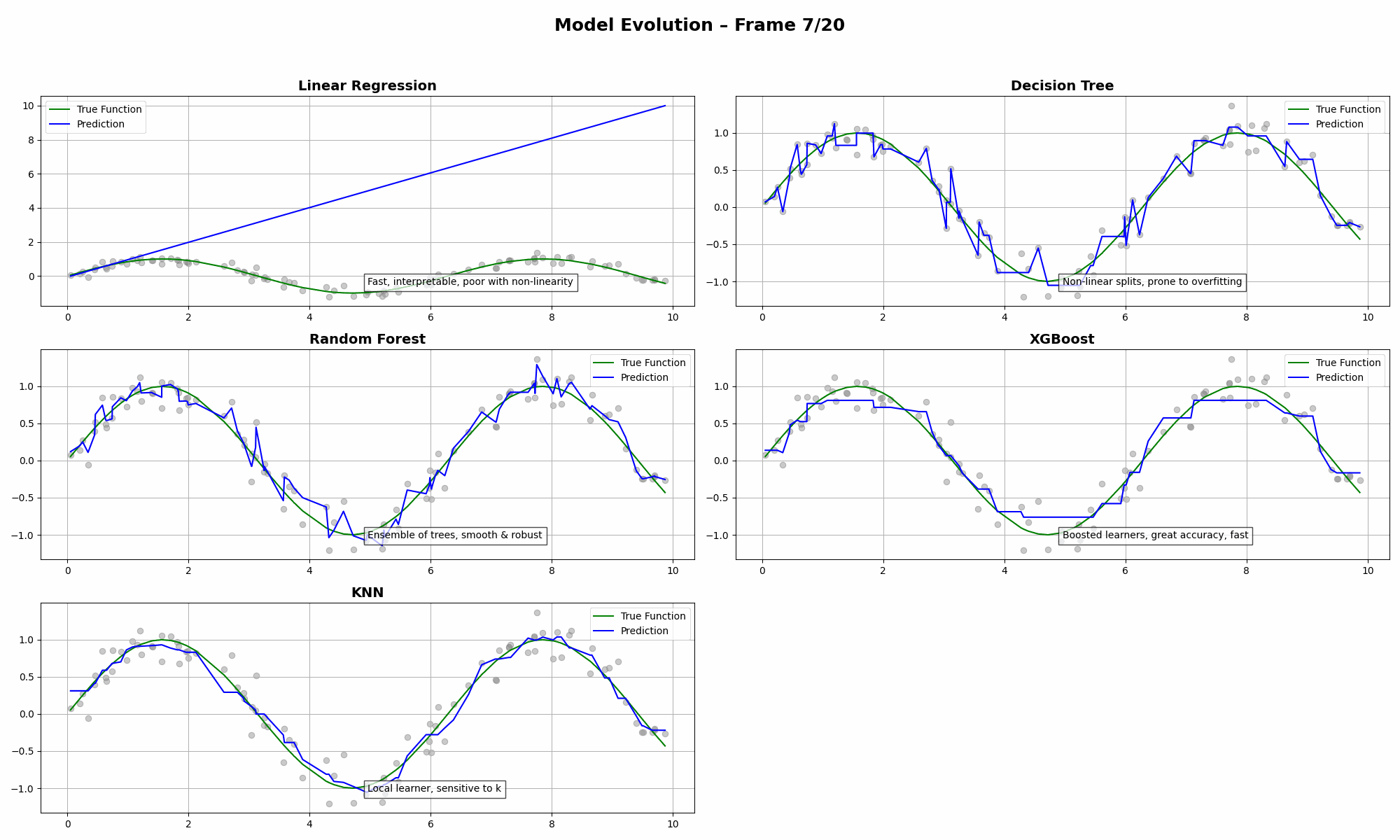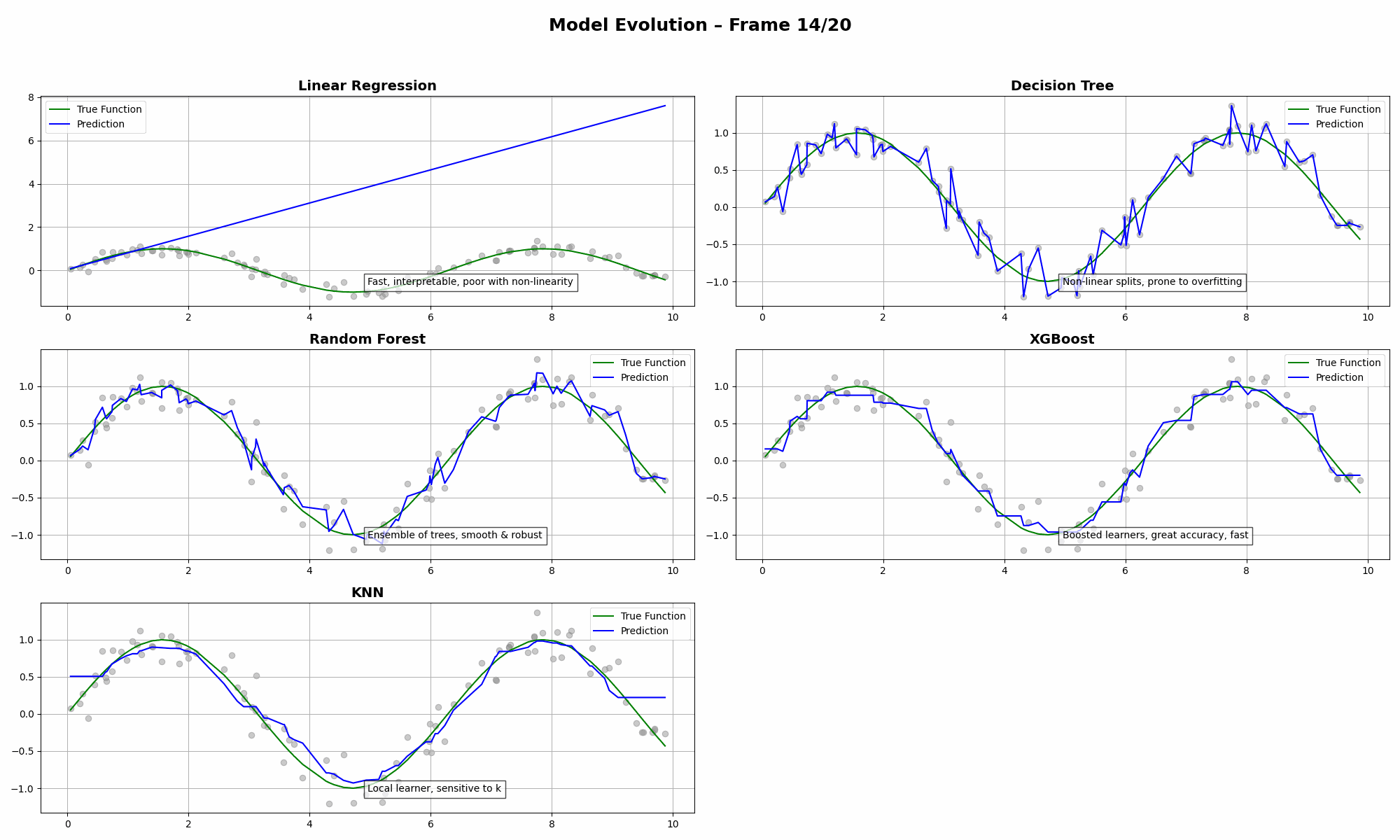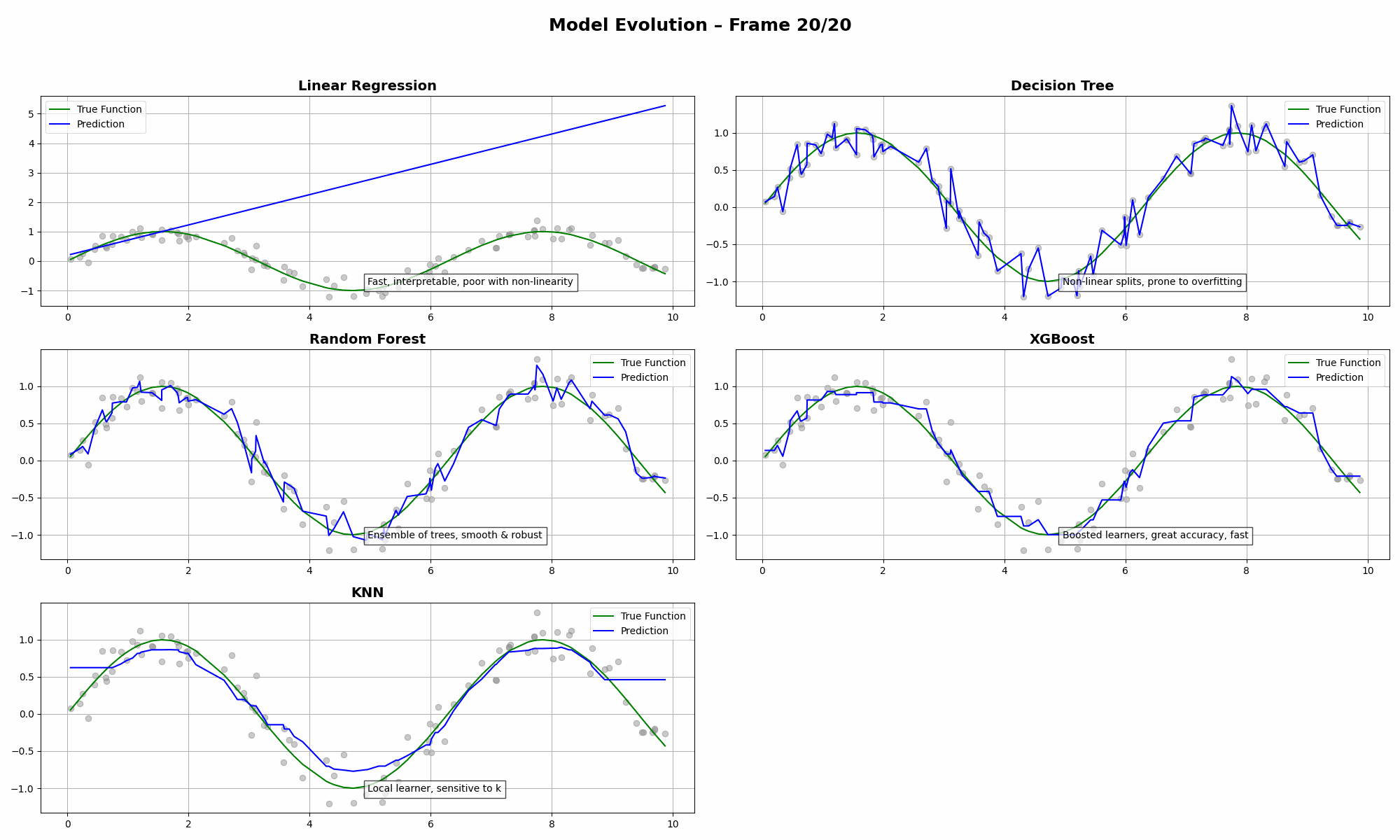
The Concepts in Play
🎯 Bias
Bias refers to the error introduced when a model makes overly simplistic assumptions about the data. In other words, it is what happens when the model is too rigid or inflexible to capture the true patterns.
Take Linear Regression for example:
“Let’s pretend everything is a straight line.”
That assumption may work in some cases, but when the data contains curves or more complex relationships, the model cannot adapt. This leads to underfitting, where the model performs poorly on both training and test data because it has failed to learn the underlying structure.
🎢 Variance
Variance measures how sensitive a model is to fluctuations or noise in the training data. A high variance model learns the data too well, including all the random quirks and outliers, which means it performs well on the training set but poorly on new data.
This is typical of models like Decision Trees and KNN:
“I will memorize your quirks and your noise.”
These models often produce excellent training scores but fall apart during testing. That gap in performance is a red flag for overfitting, where the model has essentially memorized instead of generalized.
🤹 Model Complexity
Model complexity describes how flexible a model is in fitting the data. A more complex model can capture intricate patterns and relationships, but that flexibility comes at a cost.
More complexity often means the model has a higher risk of chasing noise rather than signal. It may give impressive training performance but fail when deployed in the real world. Complex models also tend to be harder to interpret and require more data to train effectively.
So while complexity sounds appealing, it is not always the answer. Sometimes the simplest model, with fewer moving parts, delivers the most reliable results.
💡 What We Learn from the GIF
- Linear Regression has high bias. It’s smooth but can’t capture curves.
- Decision Tree slices the data too rigidly. Prone to overfitting.
- Random Forest balances bias and variance quite well (💪).
- XGBoost tries to win—but often needs careful tuning to avoid bias.
- KNN loves to follow the data closely, sometimes too closely.
Why This Matters (a lot)
In the real world:
- Underfitting leads to useless predictions.
- Overfitting leads to confident but wrong predictions.
- Balanced models win in production.
Understanding the bias-variance tradeoff helps you:
✅ Pick the right model
✅ Avoid overcomplicating
✅ Diagnose errors
✅ Not trust every “98% R² score” you see on LinkedIn
Final Thoughts
Model performance isn’t magic—it’s tradeoffs. Sometimes the simplest model wins because the data is solid. Other times, the fanciest algorithm trips on its own complexity.
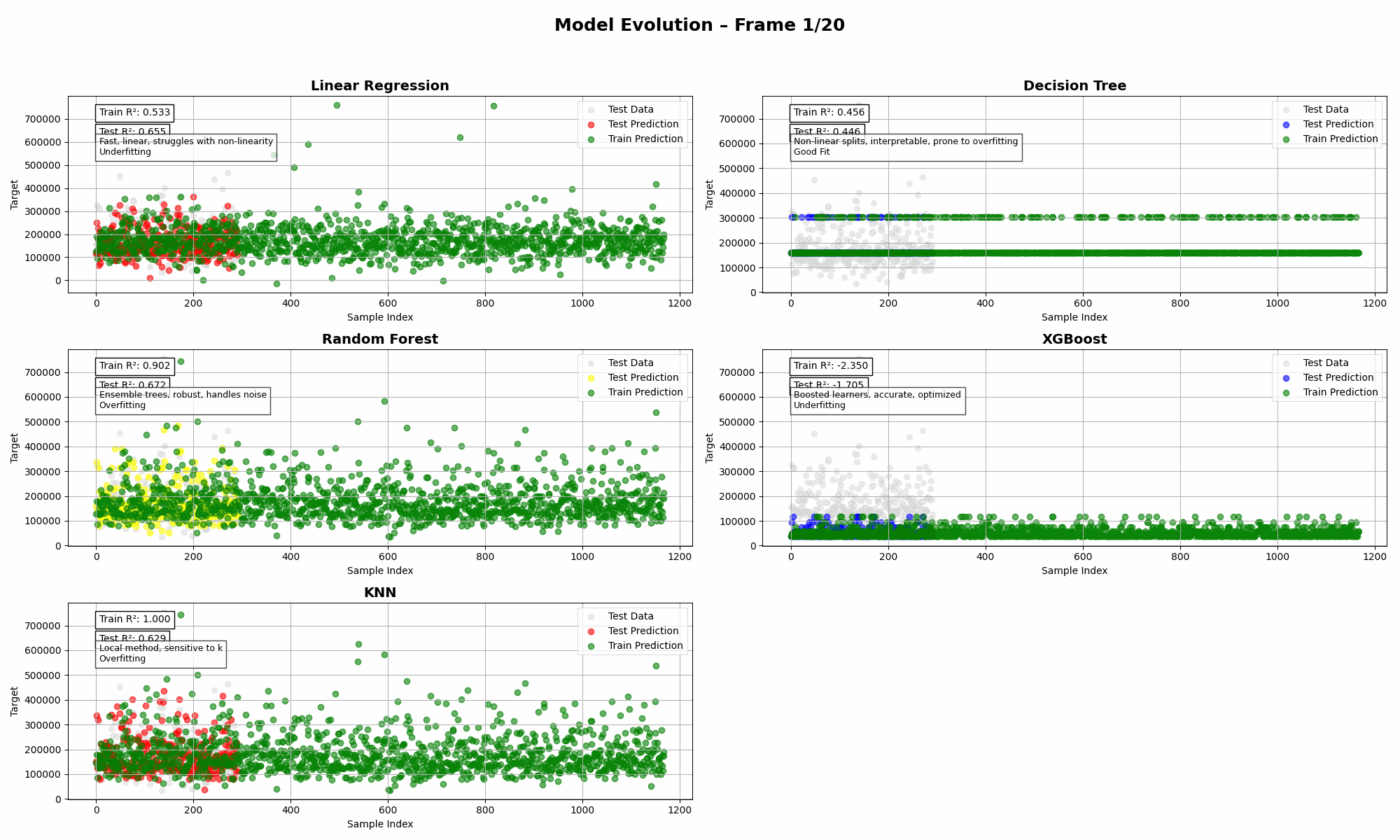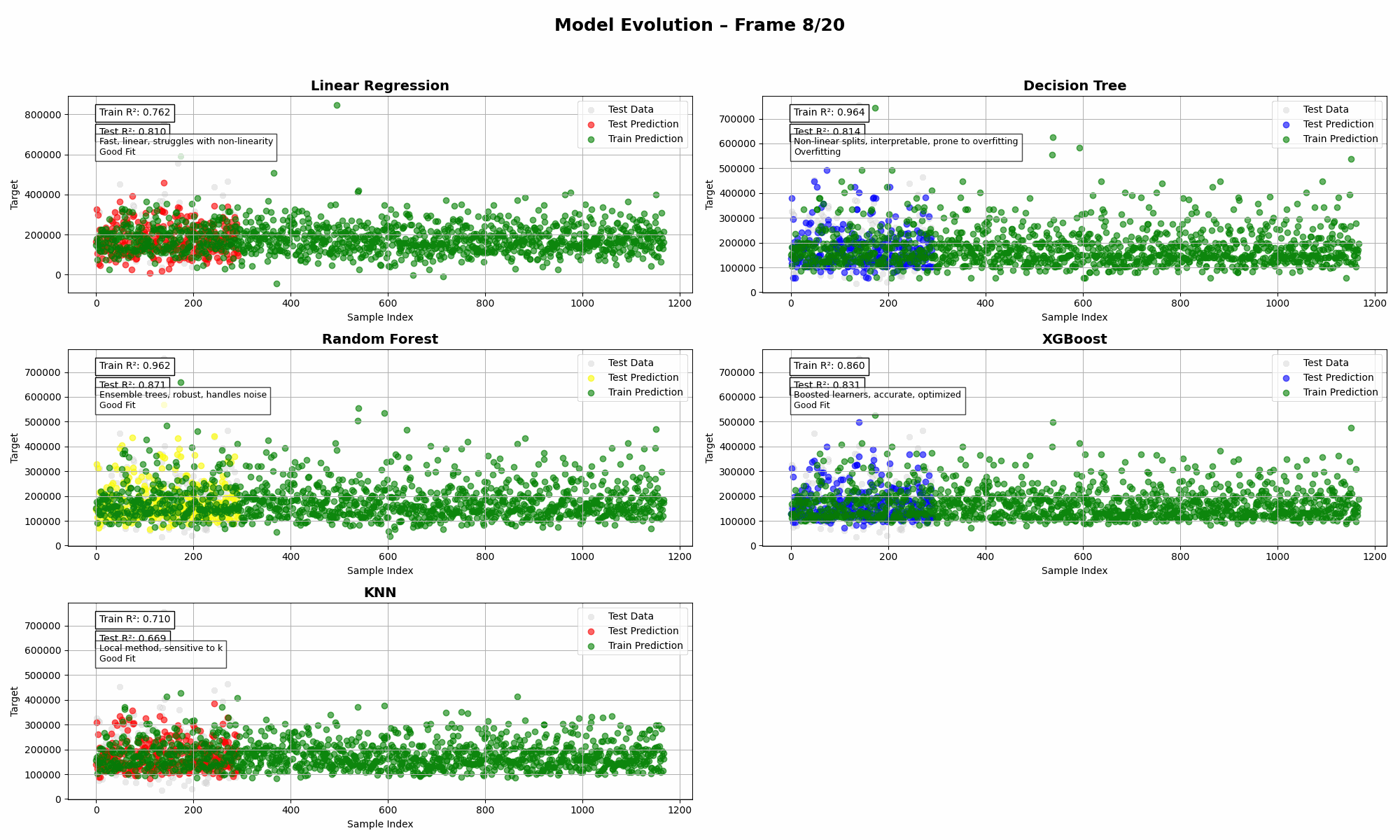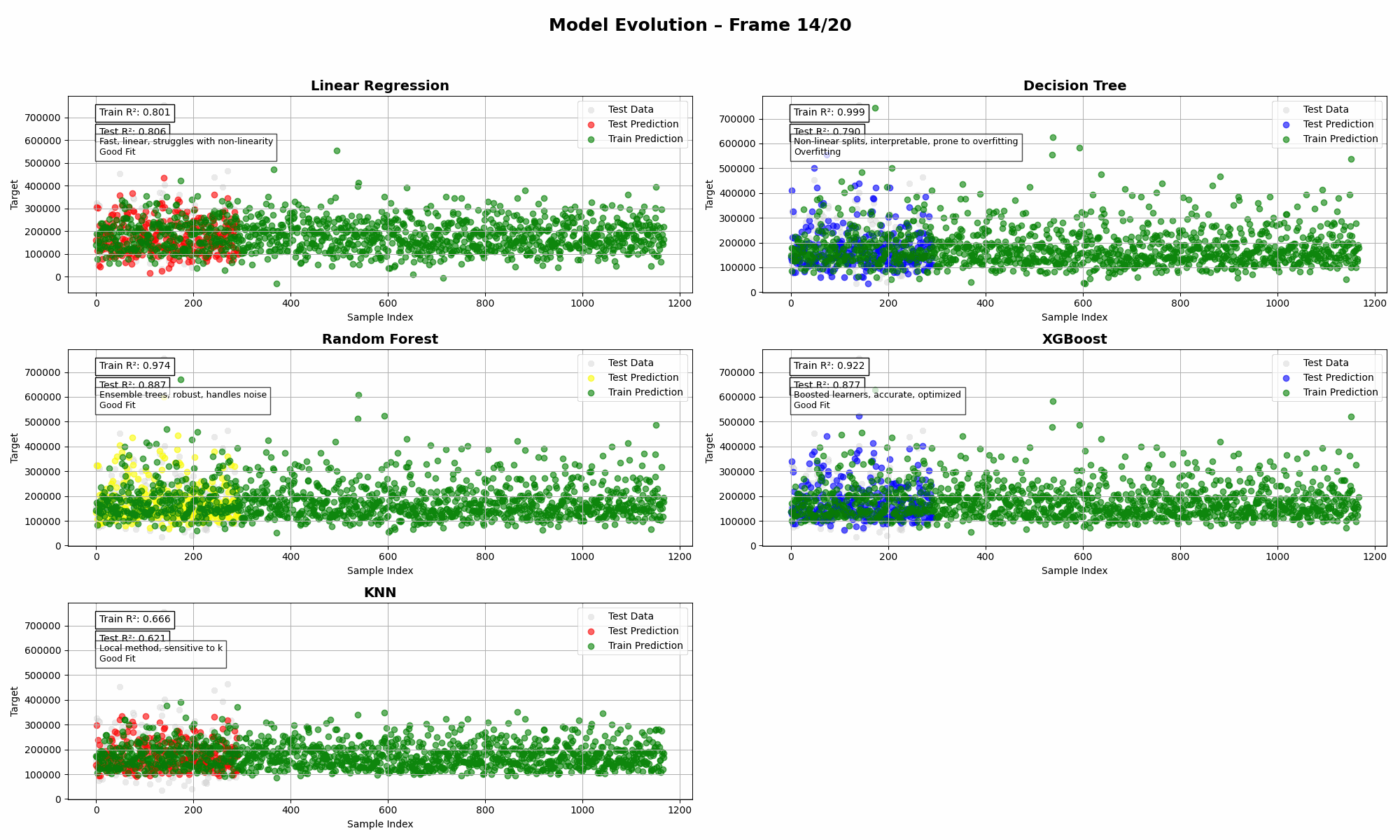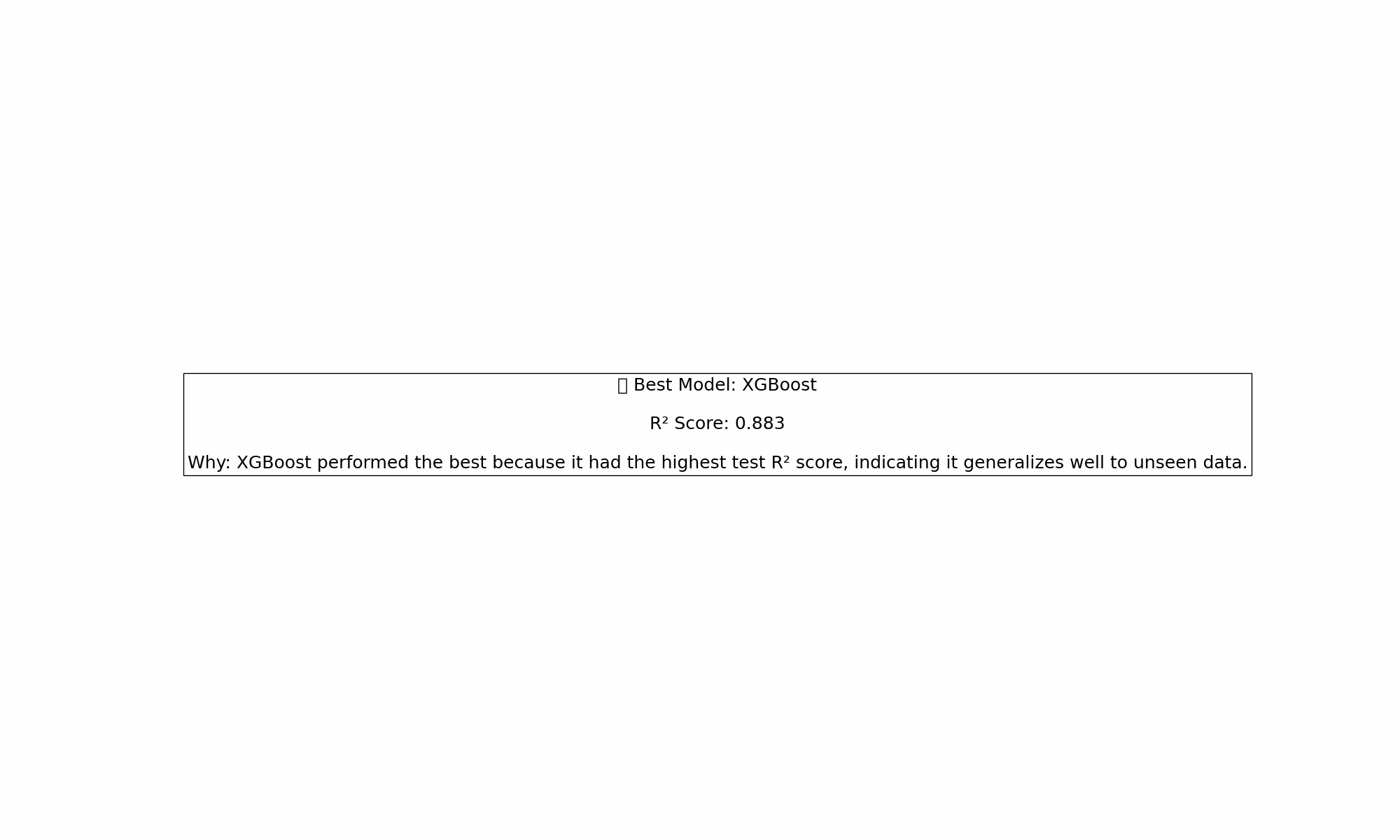
📩 Which model do you think performed best here?
Hit me up with your thoughts or overfitting horror stories.
#MachineLearning #BiasVariance #RegressionModels #ModelComplexity #XGBoost #RandomForest #KNN #Overfitting #Underfitting #DataScience